一、File类
既能代表一个特定文件的名称,又能代表一组文件的名称。
1、目录列表器
可以通过java.utils.Arrays.sort()和String.CASE_INSENSITIVE_ORDER排序。
public class DirList {public static void main(String[] args) {File path = new File(".");String[] list;if(args.length == 0)list = path.list();elselist = path.list(new DirFilter(args[0]));Arrays.sort(list, String.CASE_INSENSITIVE_ORDER);for(String dirItem : list)System.out.println(dirItem);}}class DirFilter implements FilenameFilter {private Pattern pattern;public DirFilter(String regex) {pattern = Pattern.compile(regex);}public boolean accept(File dir, String name) {return pattern.matcher(name).matches();}}
DirFilter这个类存在的唯一原因是将accept()方法。这种结构常常称为回调。这是一个策略模式的例子,以便完善list()在提供服务时所需的算法。
匿名内部类
filter()的参数必须是final的。
2、目录实用工具
运用正则表达式。
3、目录检查及创建
参照JDK。
二、输入和输出
编程语言的I/O类库中常使用流这个抽象概念,它代表任何有能力产出数据的数据源对象或者是有能力接收数据的接收端对象。“流”屏蔽了实际的I/O设备中处理数据的细节。
通过叠合多个对象提供所期望的功能(装饰器设计模式)。
1、InputStream类型
数据源包括:
- 字节数组;
String对象;- 文件;
- “管道”,工作方式与实际管道相似,即从一端输入,从另一端输出;
- 一个由其它种类的流组成的序列,以便我们可以将它们集合并到一个流内;
- 其它数据源,如Internet连接等。
| 类 | 功能 | 构造器参数 如何使用 |
|---|---|---|
ByteArrayInputStream |
允许将内存的缓冲区当作InputStream使用 |
缓冲区,字节从中取出作为一种数据源:将其与FilterInputStream对象相连以提供有用的接口 |
StringBufferInputStream |
将String转换成InputStream |
字符串,底层实现使用StringBuffer作为一种数据源:将其与FilterInputStream对象相连以提供有用的接口 |
FileInputStream |
用于从文件中读取信息 | 字符串,表示文件名、文件或FileDescriptor对象作为一种数据源:将其与FilterInputStream对象相连以提供有用的接口 |
PipedInputStream |
产生用于写入相关PipedOutputStream的数据。实现“管道化”概念 |
PipedOutputStream作为多线程中数据源:将其与FilterInputStream对象相连以提供有用的接口 |
SequenceInputStream |
将两个或者多个InputStream对象装换成单一InputStream |
两个InputStream对象或者一个容纳InputStream对象的容器Enumeration 作为一种数据源:将其与 FilterInputStream对象相连以提供有用的接口 |
FilterInputStream |
抽象类,作为“装饰器”的接口。其中,“装饰器”为其它的InputStream类提供有用的功能。 |
2、OutputStream类型
| 类 | 功能 | 构造器参数 如何使用 |
|---|---|---|
ByteArrayOutputStream |
在内存中创建缓冲区。所有送往“流”的数据都要放置在此缓冲区 | 缓冲区初始化大小(可选) 指定数据的目的地:将其与 FilterOutputStream对象相连以提供有用接口 |
FileOutputStream |
用于将信息写至文件 | 字符串,表示文件名、文件或FileDescriptor对象指定数据的目的地:将其与 FilterOutputStream对象相连以提供有用接口 |
PipedOutputStream |
任何写入其中的信息都会自动作为相关PipedInputStream的输出。实现“管道化”概念 |
PipedInputStream指定多线程的数据的目的地:将其与FilterOutputStream对象相连以提供有用接口 |
FilterOutputStream |
抽象类,作为“装饰器”的接口。其中,“装饰器”为其它的OutputStream类提供有用的功能。 |
三、添加属性和有用的接口
Java I/O类库里存在Filter(过滤器)类是需要多种不同功能的组合,抽象类Filter是所有装饰器类的基类。
装饰器的缺点:在编写程序时,它给我们提供了相当多的灵活性,但是它同时也增加了代码的复杂性。
FilterInputStream和FilterOutputStream是用来提供装饰器类接口以控制特定输入流(InputStream)和输出流(OutputStream)的两个类。
FilterInputStream和FilterOutputStream分别自I/O类库中的基类InputStream和OutputStream派生而来,这两个类是装饰器的必要条件。
1、通过FilterInputStream从InputStream读取数据
| 类 | 功能 | 构造器参数 如何使用 |
|---|---|---|
DataInputStream |
与DataOutputStream搭配使用,因此我们可以按照可移植方式从流读取基本数据类型 |
InputStream包含用于读取(read)基本数据类型的全部接口 |
BufferedInputStream |
使用它可以防止每次读取时都得进行实际读写操作。代表使用缓冲区 | InputStream,可以指定缓冲区大小(可选本质不提供接口,只不过是向进程中添加缓冲区是必须的。与接口对象搭配 |
LineNumberInputStream |
跟踪输入流的行号,可调用getLineNumber()和setLineNumber(int) |
InputStream仅增加了行号,因此可能要与接口对象搭配使用 |
PushbackInputStream |
具有“能弹出一个字节的缓冲区”。因此可以将读到的最后一个字符回退 | InputStream通常作为编译器的扫描器,之所以包含在内是因为Java编译器的需要,我们可能永远不会用到 |
2、通过FilterOutputStream向OutputStream写入
| 类 | 功能 | 构造器参数 如何使用 |
|---|---|---|
DataOutputStream |
与DataInputStream搭配使用,因此我们可以按照可移植方式写入基本数据类型 |
OutputStream包含用于写入(write)基本数据类型的全部接口 |
PrintStream |
用于产生格式化输出。其中DataOutputStream处理数据的存储,PrintStream处理显示 |
OutputStream,可以用布尔值表示是否在每次换行时清空缓冲区(可选)应该是对 OutputStream对象的final封装。可能会经常使用它 |
BufferedOutputStream |
使用它以避免每次发送数据时都要进行实际的写操作。代表使用缓冲区,可以调用flush()清空缓冲区 |
OutputStream,可以指定缓冲区大小(可选)本质不提供接口,只不过是向进程中添加缓冲区是必须的。与接口对象搭配 |
四、Reader和Writer
InputStream和OutputStream在以面向字节形式的I/O中仍可以提供有价值的功能,Reader和Writer则提供兼容Unicode与面向字符的I/O功能。此外:
- Java 1.1向
InputStream和OutputStream继承层次结构中添加了一些新类。 - 有时候必须把来自字节层次结构中的类和字符层次结构中的类结合起来使用。
InputStreamReader可以把InputStream转化为Reader,而OutputStreamWriter可以把OutputStream转化为Writer。
设计Reader和Writer主要是为了国际化。
byte(1个字节),char(2个字节,16位的Unicode)
1、数据的来源和去处
尽量尝试使用Reader和Writer,一旦程序代码无法成功编译,我们就会发现自己不得不使用面向字节的类库。
| 来源与去处:Java 1.0类 | 相应的 Java 1.1类 |
|---|---|
InputStream |
Reader适配器: InputStreamReader |
OutputStream |
Writer适配器: OutputStreamWriter |
FileInputStream |
FileReader |
FileOutputStream |
FileWriter |
StringBufferInputStream(弃用) |
StringReader |
| (无) | StringWriter |
ByteArrayInputStream |
CharArrayReader |
ByteArrayOutputStream |
CharArrayWriter |
PipedInputStream |
PipedReader |
PipedOutputStream |
PipedWriter |
2、更改流的行为
| 过滤器:Java 1.0类 | 相应的 Java 1.1类 |
|---|---|
FilterInputStream |
FilterReader |
FilterOutputStream |
FilterWriter(抽象类,没有子类) |
BufferedInputStream |
BufferedReader(也有readLine()) |
BufferedOutputStream |
BufferedWriter |
DataInputStream |
使用DataInputStream(除了当需要使用readLine()时以外,这时应该使用BufferedReader) |
PrintStream |
PrintWriter |
LineNunberInputStream(弃用) |
LineNunberReader |
StreamTokenizer |
StreamTokenizer(使用接受Reader的构造器) |
PushbackInputStream |
PushbackReader |
3、未发生变化的类
| 以下这些Java 1.0类在Java 1.1中没有相应的类 |
|---|
DataOutputStream |
File |
RandomAccessFile |
SequenceInputStream |
六、I/O流的典型使用方式
1、缓冲输入文件
BufferedReader in = new BufferedReader(new FileReader(filename));
2、从内存输入
String s;StringBuilder sb=new StringBuilder();while((s = in.readLine())!= null)sb.append(s + "\n");in.close();StringReader sin=new StringReader(sb.toString());//...
3、格式化的内存输入
DataInputStream in=new DataInputStream(new ByteArrayInputStream(sb.toString().getBytes()));while(true){in.readByte();}DataInputStream in=new DataInputStream(new BufferedInputStream(sb.toString()));while(in.available()!=0){in.readByte();}
4、基本的文件输出
PrintWriter out=new PrintWriter(new BufferedWriter(new FileWriter(file)));
如果我们不为所有的输出文件调用close(),就会发现缓冲区内容不会被刷新清空,那么它们也就不完整。
文本文件输出的快捷方式
PrintWriter out=new PrintWriter(file);//文本文件
5、存储和恢复数据
当我们使用DataOutputStream时,写字符串并且让DataInputStream能够恢复它的唯一可靠做法就是使用UTF-8编码(readUTF()和writeUTF()),UTF-8将ASCII字符编码成单一字节形式,而非ASCII字符则编码成两到三个字节的形式。另外,字符串的长度存储在UTF-8字符串的前2个字节中。
6、读写随机访问文件
使用RandomAccessFile,类似于组合使用了DataInputStream和DataOutputStream(因为它实现了相同的接口:DataInput和DataOutput)。
RandomAccessFile不允许装饰,必须假定RandomAccessFile已经被正确缓冲,因为我们不能为它添加这样的功能。
7、管道流
多线程。
七、文件读写实用工具
八、标准I/O
程序的所有输入都可以来自于标准输入,它的所有输出也都可以发送到标准输出,以及所有的错误信息都可以发送到标准错误。
1、从标准输入中读取
BufferedReader stdin=new BufferedReader (new InputStreamReader(System.in));
2、将System.out转换成PrintWriter
PrintWriter out=new PrintWriter(System.out,true);
3、标准I/O重定向
System.setIn(InputStream)
System.setOut(OutputStream)
System.setErr(OutputStream)
九、进程控制
OSExecute.command()传递一个command字符串,它与在控制台上运行该程序所键入的命令相同。这个命令传递给java.lang.ProcessBuilder构造器,然后所产生的ProcessBuilder对象被启动。
Process process=new ProcessBuilder(command.split(“ ”)).start();BufferedReader results=new BufferedReader(new InputStreamReader(process.getInputStream()));BufferedReader errors=new BufferedReader(new InputStreamReader(process.getErrorStream()));
十、新I/O
JDK 1.4的java.nio.*引入了新的Java I/O类库,其目的在于提高速度。实际上,旧的I/O包已经使用nio重新实现过,以便充分利用这种速度的提高。
速度的提高来自于所使用的结构更接近于操作系统执行I/O的方式:通道与缓冲器。
通道要么从缓冲器中获得数据,要么向缓冲器中发送数据。
唯一直接与通道交互的缓冲器是ByteBuffer,即可以存储未加工字节的缓冲器。
旧的I/O类库中FileInputStream、FileOutputStream及RandomAccessFile被修改了,用以产生FileChannel。
Reader和Writer这种字符模式类不能用于产生通道;但是java.nio.Channels类提供了实用方法,用以在通道中产生Reader和Writer。
通道是一个基础的东西:可以向它传送用于读写的ByteBuffer,并且可以锁定文件的某些区域用于独占式访问。
将字节存在于ByteBuffer中的方法之一是:使用一种put方法直接对它们进行填充,填入一个或多个字节,或基本数据类型的值。也可以用wrap()方法将已存在的字节数组“包装”到ByteBuffer中。
nio的目标就是快速移动大量数据,因此ByteBuffer的大小就显得尤为重要。
达到更高的速度也有可能,使用allocateDirect()而不是allocate(),以产生一个与操作系统有更高耦合性的“直接”缓冲器。
一旦调用read()来告知FileChannel向ByteBuffer存储字节,就必须调用缓冲器上的flip(),让它做好让别人读取字节的准备。
transferTo()和transferFrom()允许我们将一个通道和另一个通道直接相连。
1、转换数据
缓冲器容纳的是普通的字节,为了把它们装换成字符,我们要么在输入它们的时候对其进行编码,要么将在将其从缓冲器输出时对它们进行解码。
如果我们想对缓冲器调用rewind()方法,接着使用平台的默认字符集对数据进行decode(),那么作为结果的CharBuffer可以很好地输出打印到控制台。
2、获取基本类型
ByteBuffer bb=ByteBuffer.allocate(1024);//...bb.asShortBuffer().put((short)45);//...bb.getShort();
3、视图缓冲器
视图缓冲器可以让我们通过某个特定的基本数据类型的视窗查看其底层的ByteBuffer。ByteBuffer依然是实际存储数据的地方,“支持”着前面的视图,因此,对视图的任何修改都会映射成为对ByteBuffer的数据的修改。
一旦底层的ByteBuffer通过视图缓冲器填满了整数或其他基本类型时,就可以直接被写到通道中了。正像从通道中读取那么容易,然后使用视图缓冲器可以把任何数据都转化成某一特定的基本类型。
ByteBuffer bb=ByteBuffer.wrap(new Byte[]{0,0,0,0,0,0,0,’a’});//..//如下图所示IntBuffer ib=((ByteBuffer)bb.rewind()).asIntBuffer();
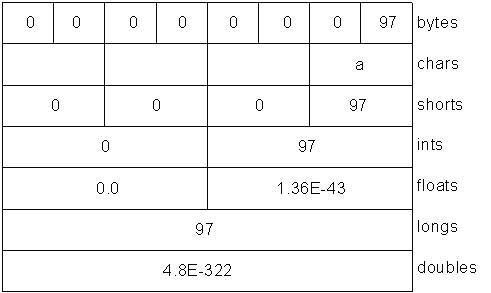
字节存放顺序
高位优先(big endian)将最重要的字节存放在地址最低的存储单元。
低位优先(little endian)将最重要的字节存放在地址最高的存储单元。
ByteBuffer是以高位优先的形式存储结构的,并且数据在网上传送时也常常使用高位优先的形式。
4、用缓冲器操纵数据
ByteBuffer是将数据迁移出通道的唯一方式,并且我们只能创建一个独立的基本类型缓冲器转换成ByteBuffer。
5、缓冲器细节
capacity( )返回缓冲区容量。clear( )清空缓冲区,将position设置为0,limit设置为容量。可以调用此方法覆写缓冲区。flip( )将limit设置为position,position设置为0。此方法用于准备从缓冲区读取已经写入的数据limit( )返回limit值。limit(int lim)设置limit值。mark( )将mark设置为position。position( )返回position值。position(int pos)设置position值。remaining( )返回 (limit - position).hasRemaining( ) 若有介于position和limit之间的元素,则返回true`。
nio之间的关系如下图所示:
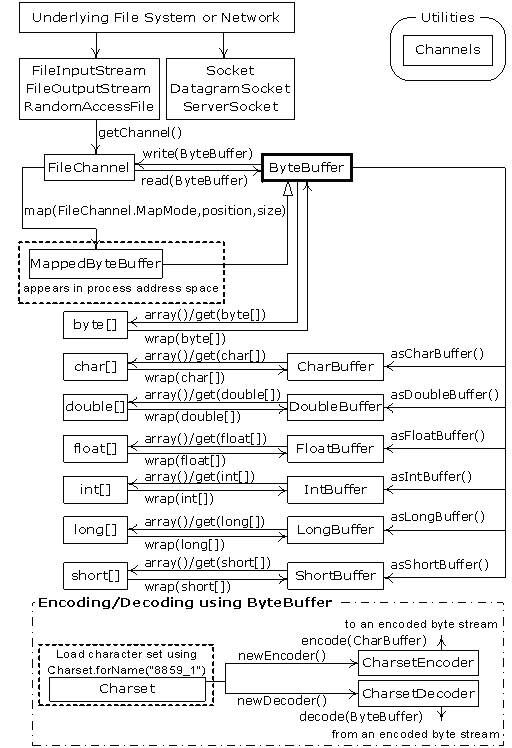
6、内存映射文件
内存映射文件允许我们创建和修改那些因为太大而不能放入内存的文件。
性能
“映射文件访问”往往可以更加显著地加快速度。
7、文件加锁
JDK 1.4引入了文件加锁机制,允许我们同步访问某个作为共享资源的文件。
文件锁对其他的操作系统进程是可见的,因为Java的文件加锁直接映射到了本地操作系统的加锁工具。
无参数的lock()加锁方法会对整个文件进行加锁。
对独占锁或者共享锁的支持必须由底层的操作系统提供。
对映射文件的部分加锁
FileChannel fc=new RandomAccessFile(“test.dat”,”rw”).getChannel();FileLock fl=fc.lock(start,end,false);
lock()调用类似于获得一个对象的线程锁—我们现在处于“临界区”,即对该部分的文件具有独占访问权。
十一、压缩
1、用GZIP进行简单压缩
把面向字符的流和面向字节的流混合起来;输入(in)用Reader类,而GZIPOutputStream的构造器只能接受OutputStream对象,不能接受Writer对象。
2、用Zip进行多文件保存
GZIP或Zip库的使用并不仅仅局限于文件—它可以压缩任何东西,包括需要通过网络发送的数据。
3、Java档案文件 JAR
十二、对象序列化
可以通过将信息写入文件或数据库恢复对象,如果能够将一个对象声明为“持久性”的,并处理掉所有细节,那么就显得十分方便。
Java的对象序列化将那些实现了Serializable接口的对象转换成一个字节序列,并能够在以后这个字节序列完全恢复为原来的对象,这一过程也可以通过网络进行。
对象的序列化是非常有趣的,因为可以利用它实现轻量级持久性。
对象必须在程序中显式地序列化和反序列化还原。
对象序列化是为了支持两种主要特性:
- 远程方法调用(Remote Method Invocation, RMI),它使存活于其他计算机上的对象使用起来就像是存活在本机上一样。
- 对Java Beans来说,对象的序列化也是必须的。使用
Bean时,一般情况下是在设计阶段对它的状态信息进行配置。这种状态信息必须保持下来,并在程序启动时进行后期恢复。
对象序列化聪明的地方是不仅仅保持了对象的全景图,而且能追踪对象内所包含的所有引用,并保存那些对象;接着又能对对象内包含的每个这样的引用进行追踪;以此类推。
ObjectOutput out = new ObjectOutputStream(response.getOutputStream());out.writeObject(obj);ObjectInput in = new ObjectInputStream(connection.getInputStream());Object obj = in.readObject();
1、寻找类
必须保证Java虚拟机能够找到相关的.class文件。
2、序列化的控制
特殊情况下,可以通过实现Externalizable接口代替实现Serializable接口,来对序列化过程进行控制。
transient关键字
transient关键字关闭序列化,意思是“不用麻烦你保存或恢复数据—我自己会处理的”。
Externalizable的替代方法
可以实现Serializable接口,并添加名为writeObject()和readObject()的方法。一旦对象被序列化或者被反序列化,就会自动调用者两个方法。(不使用默认的序列化机制)
3、使用“持久性”
只要将任何对象序列化到单一的流中,就可以恢复出与我们写入时一样的对象网,并且没有任何意外重复复制出的对象。
十三、XML
对象序列化的一个重要限制是它只是Java的解决方案:只有Java程序才能反序列化这种对象。
将数据转换成XML格式,使其被各种各样的平台和语言通用。
十四、Preferences
Preferences API与对象序列化相比,前者与对象持久性更密切,它能自动存储和读取信息。但它只能用于小的、受限的数据集合—只能存储基本类型和字符串,并且每个字符串的长度不能超过8K。
Preferences API适用于存储和读取用户的偏好以及程序配置项的设置。
十五、总结
我们可以通过控制台、文件、内存块,甚至是网络进行读写。
通过继承,我们可以创建新类型的输入和输出对象。并且通过重新定义toString()方法,我们甚至可以对流接受的对象类型进行简单扩充。
当我们打开一个文件用于输出时,我们可以指定一旦试图覆盖该文件就抛出异常。
“装饰器”模式。
Java SE5中添加了输出格式化。